
Pengertian dan Penjelasan Mengenai Regresi Logistik
Dalam sebuah penelitian biasanya kita memodelkan hubungan antar 2 variabel, yaiitu variabel X (independent) dan Y (dependent). Metode yang biasa dipakai dalam penelitian seperti ini adalah regresi linier, baik sederhana maupun berganda. Namun, adakalanya regresi linier dengan metode OLS (Ordinary Least Square) yang dipakai tidak sesuai untuk digunakan. Regresi linier yang sering digunakan kadang terjadi pelanggaran asumsi Gauss-Markov. Misalnya pada kasus dimana variabel dependent (Y) bertipe data nominal, sedangkan variabel bebas/prediktornya (X) bertipe data interval atau rasio.

Ingin diketahui apakah mahasiswa sudah melek keuangan berdasarkan jenis kelamin, fakultas yang dipilih dan indeks prestasi kumulatif. Dalam kasus ini hanya ada 2 kemungkinan respon mahasiswa, yaitu mahasiswa melek keuangan dan mahasiswa tidak melek keuangan.
Dari contoh kasus di atas, dapat diketahui bahwa tipe data variabel respon (Y) adalah nominal, yaitu kategorisasi keputusan mahasiswa melek keuangan atau tidak (misal melek keuangan angka 1, sedangkan tidak melek keuangan angka 0), sedangkan tipe data untuk variabel bebas (X) setidak- tidaknya interval (skala likert). Bila metode regresi linier biasa diterapkan pada kasus semacam ini, menurut Kutner, dkk. (2004), akan terdapat 2 pelanggaran asumsi Gauss-Markov dan 1 buah pelanggaran terhadap batasan dari nilai duga (fitted value) dari variabel respon (Y), yaitu:
- Error dari model regresi yang didapat tidak menyebar normal.
- Ragam (variance) dari error tidak homogen (terjadi heteroskedastisitas pada ragam error).
- Sedangkan, pelanggaran bagi batasan nilai duga Y (fitted value) adalah bahwa nilai duga yang dihasilkan dari model regresi linier biasa melebihi rentang antara 0 s.d. 1.
probabilitas kejadian suatu peristiwa dengan mencocokkan data pada fungsi logit kurva logistik.
Regresi logistik adalah sebuah pendekatan untuk membuat model prediksi seperti halnya regresi linear atau yang biasa disebut dengan istilah Ordinary Least Squares (OLS) regression. Perbedaannya adalah pada regresi logistik, peneliti memprediksi variabel terikat yang berskala dikotomi. Skala dikotomi yang dimaksud adalah skala data nominal dengan dua kategori, misalnya: Ya dan Tidak, Baik dan Buruk atau Tinggi dan Rendah.
Apabila pada OLS mewajibkan syarat atau asumsi bahwa error varians (residual) terdistribusi secara normal. Sebaliknya, pada regresi logistik tidak dibutuhkan asumsi tersebut sebab pada regresi logistik mengikuti distribusi logistik.
Asumsi yang harus dipenuhi dalam Regresi Logistik antara lain:
- Regresi logistik tidak membutuhkan hubungan linier antara variabel independen dengan variabel dependen.
- Variabel independen tidak memerlukan asumsi multivariate normality.
- Asumsi homokedastisitas tidak diperlukan
- Variabel bebas tidak perlu diubah ke dalam bentuk metrik (interval atau skala ratio).
- Variabel dependen harus bersifat dikotomi (2 kategori, misal: tinggi dan rendah atau baik dan buruk)
- Variabel independen tidak harus memiliki keragaman yang sama antar kelompok variabel
- Kategori dalam variabel independen harus terpisah satu sama lain atau bersifat eksklusif
- Sampel yang diperlukan dalam jumlah relatif besar, minimum dibutuhkan hingga 50 sampel data untuk sebuah variabel prediktor (independen).
- Regresi logistik dapat menyeleksi hubungan karena menggunakan pendekatan non linier log transformasi untuk memprediksi odds ratio. Odd dalam regresi logistik sering dinyatakan sebagai probabilitas.
Sebagaimana metode regresi biasa, Regresi Logistik dapat dibedakan menjadi 2, yaitu:
- Binary Logistic Regression (Regresi Logistik Biner). Regresi Logistik biner digunakan ketika hanya ada 2 kemungkinan variabel respon (Y), misal membeli dan tidak membeli.
- Multinomial Logistic Regression (Regresi Logistik Multinomial). Regresi Logistik Multinomial digunakan ketika pada variabel respon (Y) terdapat lebih dari 2 kategorisasi.
Berikut persamaannya regresi logistic :

Di mana:
Ln : Logaritma Natural.
B0 + B1X : Persamaan yang biasa dikenal dalam OLS.
Ln : Logaritma Natural.
B0 + B1X : Persamaan yang biasa dikenal dalam OLS.
Sedangkan P Aksen adalah probabilitas logistik yang didapat rumus probabilitas regresi logistic sebagai berikut:
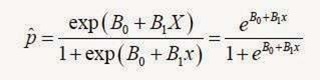
Di mana:
exp atau ditulis "e" adalah fungsi exponen.
(Perlu diingat bahwa exponen merupakan kebalikan dari logaritma natural. Sedangkan logaritma natural adalah bentuk logaritma namun dengan nilai konstanta 2,71828182845904 atau biasa dibulatkan menjadi 2,72).
exp atau ditulis "e" adalah fungsi exponen.
(Perlu diingat bahwa exponen merupakan kebalikan dari logaritma natural. Sedangkan logaritma natural adalah bentuk logaritma namun dengan nilai konstanta 2,71828182845904 atau biasa dibulatkan menjadi 2,72).
Dengan model persamaan di atas, tentunya akan sangat sulit untuk menginterprestasikan koefisien regresinya. Oleh karena itu maka diperkenalkanlah istilah Odds Ratio atau yang biasa disingkat Exp(B) atau OR. Exp(B) merupakan exponen dari koefisien regresi. Jadi misalkan nilai slope dari regresi adalah sebesar 0,80, maka Exp(B) dapat diperkirakan sebagai berikut:
2,72^0,80 = 2,23
Besarnya nilai Exp(B) dapat diartikan sebagai berikut:
Misalnya nilai Exp (B) pengaruh fakultas terhadap terhadap melek keuangan mahasiswa adalah sebesar 2,23, maka disimpulkan bahwa mahasiswa yang kuliah di fakultas ekonomi lebih menjamin untuk mahasiswa lebih melek huruf dibandingkan dengan mahasiswa yang tidak kuliah di fakultas ekonomi. Interprestasi ini diartikan apabila pengkodean kategori pada tiap variabel sebagai berikut:
Misalnya nilai Exp (B) pengaruh fakultas terhadap terhadap melek keuangan mahasiswa adalah sebesar 2,23, maka disimpulkan bahwa mahasiswa yang kuliah di fakultas ekonomi lebih menjamin untuk mahasiswa lebih melek huruf dibandingkan dengan mahasiswa yang tidak kuliah di fakultas ekonomi. Interprestasi ini diartikan apabila pengkodean kategori pada tiap variabel sebagai berikut:
- Variabel bebas adalah melek keuangan: Kode 0 untuk tidak melek keuangan, kode 1 untuk melek keuangan.
- Variabel terikat adalah fakultas: Kode 0 untuk fakultas non ekonomi, kode 1 untuk fakultas ekonomi.
Perbedaan lainnya yaitu pada regresi logistik tidak ada nilai "R Square" untuk mengukur besarnya pengaruh simultan beberapa variabel bebas terhadap variabel terikat. Dalam regresi logistik dikenal istilah Pseudo R Square, yaitu nilai R Square Semu yang maksudnya sama atau identik dengan R Square pada OLS.
Jika pada OLS menggunakan uji F Anova untuk mengukur tingkat signifikansi dan seberapa baik model persamaan yang terbentuk, maka pada regresi logistik menggunakan Nilai Chi-Square. Perhitungan nilai Chi-Square ini berdasarkan perhitungan Maximum Likelihood.
Jika pada OLS menggunakan uji F Anova untuk mengukur tingkat signifikansi dan seberapa baik model persamaan yang terbentuk, maka pada regresi logistik menggunakan Nilai Chi-Square. Perhitungan nilai Chi-Square ini berdasarkan perhitungan Maximum Likelihood.
{kind=link}